CentOS 安装 HaDoop 2.10.1 伪分布式 + Hive 3.1.2 + Spark 2.4.8
一、准备
1.1、介绍
| 名称 | 版本 | 说明 |
|---|---|---|
| centos | 7.9 | 随便无所谓 |
| openjdk | 1.8.0_291 | 版本1.8x即可 |
| hadoop | 2.10.1 | 版本自己看着办 |
| spark | 2.4.8 | 版本自己看着办 |
| hive | 3.1.2 | 版本自己看着办 |
1.2、机器规格
| CPU | 内存 | 系统盘 | 数据盘 | Mysql数据盘 |
|---|---|---|---|---|
| 16c | 64G | 200G | 6T×4 | 200G |
二、安装 OpenJDK
2.1、安装 OpenJdk
- 下载地址:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
- 找到 Linux x64 Compressed Archive 版本下载这个即可
mkdir -p /usr/java
# 解压
tar xvf jdk-8u291-linux-x64.tar.gz
# 移动到刚刚创建好目录
mv jdk1.8.0_291/ /usr/java/三、安装 HaDoop 伪分布式模式
- 伪分布式是完全分布式的特例,只有一个节点。
3.1、配置环境变量
cat <<'EOF'>> /etc/profile
# JDK
export JAVA_HOME=/usr/java/jdk1.8.0_291
export CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
# hadoop
export HADOOP_HOME=/usr/local/hadoop
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export PATH=$HADOOP_HOME/bin:$PATH
# spark
export SPARK_HOME=/usr/local/spark
export PATH=$SPARK_HOME/bin:$PATH
# hive
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
EOF
# 刷新环境变量
source /etc/profile
3.2、下载 hadoop
# 下载到本地
wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz
# 解压
tar xvf hadoop-2.10.1.tar.gz
# 移动
mv hadoop-2.10.1 /usr/local/hadoop2.4、配置文件
- 配置文件目录 /usr/local/hadoop/etc/hadoop
2.4.1、core-site.xml 配置
# 直接复制黏贴即可
cat <<'EOF'>> /usr/local/hadoop/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
</configuration>
EOF2.4.2、hdfs-site.xml 配置
- 我这里多配置路径因为我多磁盘,如果只有一个磁盘修改为一个即可
- 多磁盘配置成功会叠加,我这里每块硬盘6T,弄起来差不多20T样子
# 直接复制黏贴即可
cat <<'EOF'>> /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>
/hdfs-01/name,
/hdfs-02/name,
/hdfs-03/name,
/hdfs-04/name
</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>
/hdfs-01/data,
/hdfs-02/data,
/hdfs-03/data,
/hdfs-04/data
</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
EOF2.4.3、mapred-site.xml 配置
- 如果想使用yarn 则需要编辑下面两个配置文件
# 直接复制黏贴即可
cat <<'EOF'>> /usr/local/hadoop/etc/hadoop/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
EOF2.4.4、yarn-site.xml 配置
- 如果想使用yarn 则需要编辑下面两个配置文件
# 直接复制黏贴即可
cat <<'EOF'>> /usr/local/hadoop/etc/hadoop/yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
EOF2.4.5、hadoop-env.sh 配置
- 修改 hadoop-env.sh
- 这里自己手动去修改
vim hadoop-env.sh
将 export JAVA_HOME=${JAVA_HOME} 修改为固定地址,通过环境变量可能无法启动
export JAVA_HOME=/usr/java/jdk1.8.0_2913.3、创建相关目录
mkdir -p /usr/local/hadoop/tmp3.4、免密登录
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
# 再验证ssh localhost是否能免密登录。
root@aka:/usr/local/hadoop/etc/hadoop$ ssh localhost
Last login: Tue Jun 15 20:47:42 2021 from 112.49.185.1213.5、格式化
# 格式化只做一次即可,再次格式化会丢失datanode的数据
hdfs namenode -format3.6、启动 DFS
root@aka:~$ /usr/local/hadoop/sbin/start-dfs.sh
Starting namenodes on [localhost]
localhost: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-172-16-8-97.out
localhost: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-172-16-8-97.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-172-16-8-97.out3.7、启动 YARN
root@aka:~$ /usr/local/hadoop/sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-root-resourcemanager-172-16-8-97.out
localhost: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-172-16-8-97.out3.8、停止命令
# 停止 dfs
/usr/local/hadoop/sbin/stop-dfs.sh
# 停止 yarn
/usr/local/hadoop/sbin/stop-yarn.sh
# 停止全部
/usr/local/hadoop/sbin/stop-all.sh3.9、查看 JPS
root@aka:~$ jps
24416 SecondaryNameNode
24194 DataNode
24709 NodeManager
25063 Jps
24601 ResourceManager
24047 NameNode3.10、WEB 访问页面
| 名称 | 访问地址 |
|---|---|
| HDFS管理界面 | http://机器ip地址:50070/ |
| yarn管理界面 | http://机器ip地址:8088 |
| SecondaryNameNode管理界面 | http://机器ip地址:50090/ |
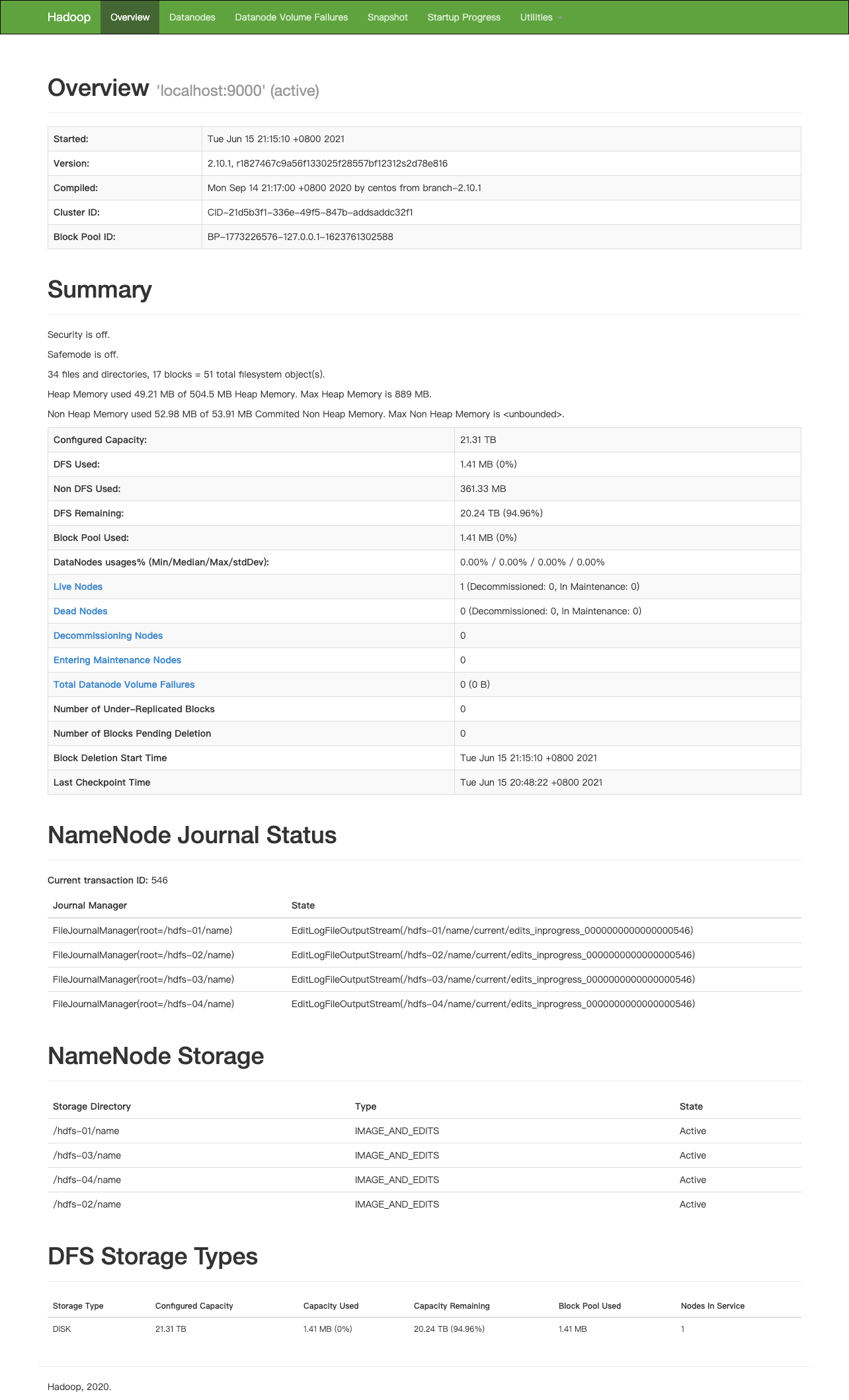
3.11、测试数据
cat <<'EOF'>> /root/hdfs_test
hello world
hello hadoop
EOF3.12、创建目录
root@aka:~$ hdfs dfs -mkdir /input
# 查看是否创建成功
root@aka:~$ hdfs dfs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2021-06-15 21:26 /input3.13、上传测试文件到 HDFS
root@aka:~$ hdfs dfs -put /root/hdfs_test /input
# 查看 hdfs 目录下文件
root@aka:~$ hdfs dfs -ls /input
Found 1 items
-rw-r--r-- 1 root supergroup 25 2021-06-15 21:28 /input/hdfs_test3.14、运行一次计算
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar wordcount /input/hdfs_test /output
# 如果报错先删除 /output
hdfs dfs -rm -r /output
# 查看结果
root@aka:~$ hdfs dfs -cat /output/part-r-00000
hadoop 1
hello 2
world 1四、Hive 安装
4.1、安装 hive
# 下载 hive
wget https://mirrors.bfsu.edu.cn/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
# 解压
tar xvf apache-hive-3.1.2-bin.tar.gz
# 移动
mv apache-hive-3.1.2-bin /usr/local/hive4.2、下载 Mysql 驱动
# 下载
wget https://cdn.mysql.com/archives/mysql-connector-java-5.1/mysql-connector-java-5.1.49.tar.gz
# 解压
tar xvf mysql-connector-java-5.1.49.tar.gz
# 移动
mv mysql-connector-java-5.1.49/mysql-connector-java-5.1.49-bin.jar /usr/local/hive/lib/4.3、配置文件修改 hive-env
# 添加以下内容
cat <<'EOF'>> /usr/local/hive/conf/hive-env.sh
# 配置HADOOP_HOME路径
export HADOOP_HOME=/usr/local/hadoop
# 配置HIVE_CONF_DIR路径
export HIVE_CONF_DIR=/usr/local/hive/conf
export HIVE_AUX_JARS_PATH=/usr/local/hive/lib
EOF4.4、配置文件修改 hive-site.xml
- 数据库要么用rds 要么自己搭建,内容看自己需求设置
cat <<'EOF'>> /usr/local/hive/conf/hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- hdfs存储目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- hdfs存储目录 -->
<property>
<name>hive.exec.scratchdir</name>
<value>/user/hive</value>
</property>
<!-- jdbc url配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://127.0.0.1:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<!-- 设置jdbc驱动 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>aka123</value>
</property>
<!-- 该属性为空表示嵌入模式或本地模式,否则为远程模式 -->
<property>
<name>hive.metastore.uris</name>
<value></value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description></description>
</property>
</configuration>
EOF4.5、HDFS 创建 Hive 目录
# 创建目录
hdfs dfs -mkdir /user/hive
hdfs dfs -mkdir /user/hive/warehouse
# 赋予权限
hdfs dfs -chmod 777 /user/hive
hdfs dfs -chmod 777 /user/hive/warehouse4.6、初始化 Hive
schematool -dbType mysql -initSchema4.7、进入 Hive 测试
# 进入 hive,只需输入 hive 即可
# 创建测试表
hive> create database db_hiveTest;
OK
Time taken: 0.603 seconds
# 显示刚刚创建的表
hive> show databases;
OK
db_hivetest
default
Time taken: 0.495 seconds, Fetched: 2 row(s)五、Spark 安装
5.1、安装 Spark
# 下载 hive
wget https://mirrors.bfsu.edu.cn/apache/spark/spark-2.4.8/spark-2.4.8-bin-hadoop2.7.tgz
# 解压
tar xvf spark-2.4.8-bin-hadoop2.7.tgz
# 移动
mv spark-2.4.8-bin-hadoop2.7 /usr/local/spark5.2、配置文件
- 根据自己需求修改
- 注意:PYSPARK_PYTHON 设置指定 python 版本,默认请注释
- 指定 Python 版本 不建议抖机灵覆盖系统自带 python 版本 否则各种错误很难说
# 复制黏贴即可
cat <<'EOF'>> /usr/local/spark/conf/spark-env.sh
#!/usr/bin/env bash
# jdk 路径
export JAVA_HOME=/usr/java/jdk1.8.0_291
# 主节点的IP
SPARK_MASTER_IP=127.0.0.1
# 主节点的端口号,用来与worker通信
SPARK_MASTER_PORT=7077
# 每一个worker进程所能管理的核数
SPARK_WORKER_CORES=3
# 每一个worker进程所能管理的内存数
SPARK_WORKER_MEMORY=2G
# 每个节点启动worker的实例数
SPARK_WORKER_INSTANCES=1
# worker的工作目录区
SPARK_WORKER_DIR=/usr/local/spark/conf
# 指定 Python 版本
export PYSPARK_PYTHON=/root/.pyenv/versions/3.6.5/bin/python
EOF
5.3、查看 JPS
- 如果出现 master 与 slave 即可
root@~$ jps
3073 NodeManager
2502 DataNode
27735 Worker
2762 SecondaryNameNode
27645 Master
2958 ResourceManager
2383 NameNode
28175 Jps5.4、使用 Spark
- 有 pyspark 和 spark 之分
- 下面演示 pyspark
- 指定 Python 版本最好用 pyenv 安装指定版本,在spark-env.sh 修改 PYSPARK_PYTHON
- 需要安装 pyen 参考这篇文章 https://www.akiraka.net/python/201.html
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.8
/_/
Using Python version 3.6.5 (default, Nov 16 2020 22:23:17)
SparkSession available as 'spark'.
>>> a="hello spark"
>>> print a
hello spark阅读剩余
版权声明:
作者:Akiraka
链接:https://www.akiraka.net/hadoop/1117.html
文章版权归作者所有,未经允许请勿转载。
THE END